Gestionar el acceso a AWS bedrock utilizando AWS Lambda y API Gateway


Desde el lanzamiento y disponibilidad de AWS Bedrock en distintas regiones [1][2], las pruebas de conceptos son necesarias para validar y probar las funcionalidades y características que ofrece el servicio.
Para agregar una capa de seguridad y límites a las invocaciones construimos un proxy utilizando AWS lambda y APIGateway en los ambientes de pruebas y testing que realizamos, sobre todo si tenemos que habilitar el servicio para otros sectores dentro de la empresa o a nuestros clientes.
⚠️ El API key siempre debería ir acompañado de una cuota(Límite de invocaciones), y en la mayoría de los casos para ambientes efímeros o de pruebas; para más seguridad siempre deberíamos agregar Autorizers a nuestras API, como AWS cognito/JWT Customs , etc.
A continuación un ejemplo de cómo agregar un proxy a AWS bedrock y exponerlo a través de una API con cuota.
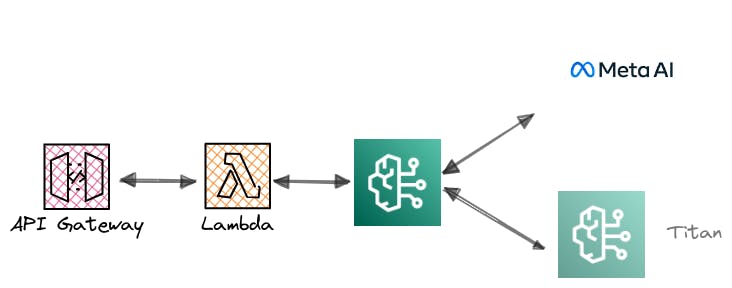
Conectarnos a AWS bedrock desde Lambda
Para conectarnos usaremos Boto3, y nos conectaremos a modo de prueba a dos de los LLM disponibles tras BedRock. Titan(amazon.titan-text-express-v1) y Llama(meta.llama2-70b-chat-v1) .
# src/client_bedrock.py
import boto3
import botocore
import json
bedrock_runtime = boto3.client('bedrock-runtime', region_name='us-east-1')
Y luego, un par de métodos para cada LLM al que queremos conectarnos, para el caso de titan(amazon.titan-text-express-v1):
# src/client_bedrock.py
def titan_model(prompt):
body = json.dumps({
"inputText": prompt,
"textGenerationConfig":{
"maxTokenCount":4096,
"stopSequences":[],
"temperature":0,
"topP":0.9
}
})
modelId = 'amazon.titan-text-express-v1' # change this to use a different version from the model provider
accept = 'application/json'
contentType = 'application/json'
outputText = "\n"
text = bedrock_runtime.invoke_model(body=body, modelId=modelId, accept=accept, contentType=contentType)
response_body = json.loads(text.get('body').read())
outputText = response_body.get('results')[0].get('outputText')
response = {"statusCode": 200, "body": json.dumps(outputText)}
return response
Para llama(meta.llama2-70b-chat-v1) usamos un método similar:
# src/client_bedrock.py
def llama_model(prompt):
body = json.dumps({
'prompt': prompt,
'max_gen_len': 512,
'top_p': 0.9,
'temperature': 0.2
})
modelId = 'meta.llama2-70b-chat-v1' # change this to use a different version from the model provider
accept = 'application/json'
contentType = 'application/json'
outputText = "\n"
response = bedrock_runtime.invoke_model(body=body, modelId=modelId, accept=accept, contentType=contentType)
response_body = json.loads(response.get('body').read().decode('utf-8'))
outputText = response_body['generation'].strip()
response = {"statusCode": 200, "body": json.dumps(outputText)}
return response
Y luego, un handler para decidir a que LLM queremos llamar:
# src/handler.py
import json
from src.client_bedrock import titan_model, llama_model
from enum import Enum
class Model(Enum):
TITAN = 'titan'
LLAMA = 'llama'
NONE = 'none'
@classmethod
def _missing_(cls, value):
return cls.NONE
def hello(event, context):
q = json.loads(event['body'])
model = Model(q['model'])
match model:
case Model.TITAN:
text = titan_model(json.dumps(q['question']))
case Model.LLAMA:
text = llama_model(json.dumps(q['question']))
case Model.NONE:
text = "Model does not match"
response = {"statusCode": 200, "body": json.dumps(text)}
return response
El despliegue y gestión de las cuotas
Para el despliegue utilicé Serverless Framework , de la configuración del Serverless Framework importante destacar:
- Configuración del API key:
apiGateway:
apiKeys:
- name: tollmkey
description: tollmkey api key # Optional
usagePlan:
quota:
limit: 100 # Limint by moth
offset: 2
period: MONTH
throttle:
burstLimit: 200
rateLimit: 100
En el proceso de deploy Serverless Framework nos muestra como salidas el nombre de la API y la API Key:
Deploying lambda-bedrock-proxy to stage dev (us-east-1)
✔ Service deployed to stack lambda-bedrock-proxy-dev (80s)
# Value of APIKEY
api keys:
tollmkey: YOURAPIKEYHERE - tollmkey api key# Optional
endpoint: GET - https://xxxxxxxxxx.execute-api.us-east-1.amazonaws.com/dev/bedrock
functions:
hello: lambda-bedrock-proxy-dev-hello (3.1 kB)
layers:
bedrock: arn:aws:lambda:us-east-1:XXXXXXXXX:layer:bedrock-dependencies:4
- Configuración de la Lambda layer: El runtime para Python de lambda toma una versión de Boto3(1.26) por default, pero para conectarse con bedrock es necesario una versión específica o superior (
boto3>=1.28.57), para esto se configuró Boto3 dentro de una layer al igual que el resto de dependencias.
# layers/tools/aws_requirements.txt
boto3>=1.28.57
awscli>=1.29.57
botocore>=1.31.57
langchain>=0.0.350
Invocar la API con el API key
Para invocar los modelos el body tiene dos campos: question y model. question es la consulta que le pasaremos al modelo y model el tipo de modelo, para este ejemplo están configurados dos modelos Titan(amazon.titan-text-express-v1) y Llama(meta.llama2-70b-chat-v1) .
curl --location 'https://YOURID.execute-api.us-east-1.amazonaws.com/dev/bedrock' \
--header 'Content-Type: application/json' \
--header 'x-api-key: YOURAPIKEY' \
--data '{
"question": "What is a dystopia",
"model": "llama"
}'
Probando el límite de la cuota
Si superamos el límite de las cuotas que definimos en el apartado Apigateway/usagePlan del serverless.yml nos indicará la respuesta de la API con un mensaje de que el límite se ha superado y un código HTTP 429
HTTP/1.1 429
Content-Type: application/json
Content-Length: 28
Connection: close
x-amzn-RequestId: 893834e6-5f4c-4bb6-95e0-a5b7f255bf51
x-amzn-ErrorType: LimitExceededException
x-amz-apigw-id: TvNwHEKSIAMEQiQ=
X-Cache: Error from cloudfront
{
"message": "Limit Exceeded"
}
Código fuente:
El ejemplo completo sobre el que escribí este resumen está en el siguiente repositorio: https://github.com/olcortesb/lambda-bedrock-proxy/tree/main
Conclusiones:
Configuramos un solo
endpointpara llamar a distintos modelos que son soportados por AWS Bedrock, se pueden extender agregando la función para cada LLM y un campo más en el EnumSe configuró una cuota para una API key y se pueden configurar distintas cuotas para distintos equipos, una cuota para cada API key
Se configuró Boto3 para usar con lambda las versiones soportadas dentro de una Lambda Layer
⚠️ Para más seguridad se podría habilitar Authorizer a la lambda con AWS Cognito o un
JWT Custom
Referencias
[1]. https://aws.amazon.com/es/about-aws/whats-new/2023/09/amazon-bedrock-generally-available/
[2]. https://aws.amazon.com/es/about-aws/whats-new/2023/10/amazon-bedrock-europe-frankfurt-aws-region/